Redis RedLock 完美的分布式锁么?
上周花了点时间研究了 Redis 的作者提的 RedLock 的算法来实现一个分布式锁,文章地址。在官方的文档最下面发现了这样一句话。
Analysis of RedLock
Martin Kleppmann analyzed Redlock here. I disagree with the analysis and posted my reply to his analysis here.
突然觉得事情好像没有那么简单,就点进去看了看。仔细读了读文章,发现了一个不得了的世界。于是静下心来研究了 Martin 对 RedLock 的批评,还有 RedLock 作者 antirez 的反击。
Martin 的批评
Martin上来就问,我们要锁来干啥呢?两个原因:
- 提升效率,用锁来保证一个任务没有必要被执行两次。比如(很昂贵的计算)
- 保证正确,使用锁来保证任务按照正常的步骤执行,防止两个节点同时操作一份数据,造成文件冲突,数据丢失。
对于第一种原因,我们对锁是有一定宽容度的,就算发生了两个节点同时工作,对系统的影响也仅仅是多付出了一些计算的成本,没什么额外的影响。这个时候 使用单点的 Redis 就能很好的解决问题,没有必要使用RedLock,维护那么多的Redis实例,提升系统的维护成本。
对于第二种原因,对正确性严格要求的场景(比如订单,或者消费),就算使用了 RedLock 算法仍然不能保证锁的正确性。
我们分析一下 RedLock 的有啥缺陷吧: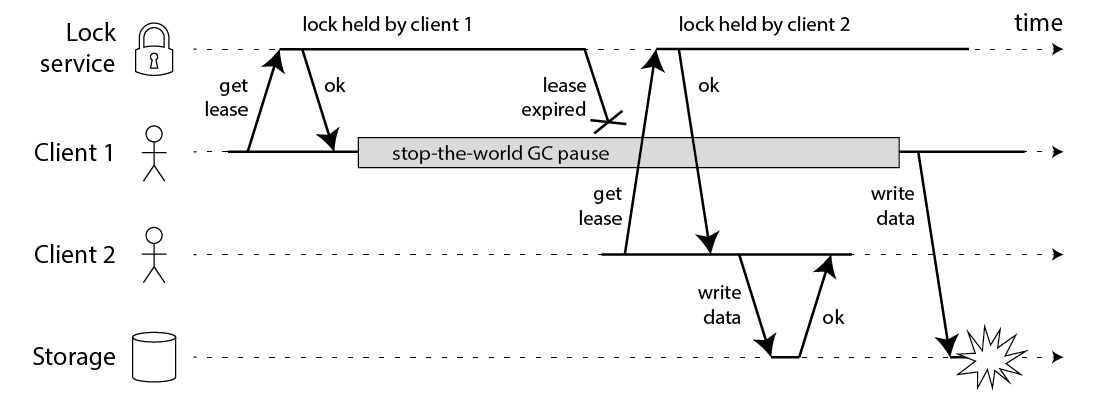
作者 Martin 给出这张图,首先我们上一讲说过,RedLock中,为了防止死锁,锁是具有过期时间的。这个过期时间被 Martin 抓住了小辫子。
- 如果 Client 1 在持有锁的时候,发生了一次很长时间的 FGC 超过了锁的过期时间。锁就被释放了。
- 这个时候 Client 2 又获得了一把锁,提交数据。
- 这个时候 Client 1 从 FGC 中苏醒过来了,又一次提交数据。
这还了得,数据就发生了错误。RedLock 只是保证了锁的高可用性,并没有保证锁的正确性。
这个时候也许你会说,如果 Client 1 在提交任务之前去查询一下锁的持有者是不自己就能解决这个问题?
答案是否定的,FGC 会发生在任何时候,如果 FGC 发生在查询之后,一样会有如上讨论的问题。
那换一个没有 GC 的编程语言?
答案还是否定的, FGC 只是造成系统停顿的原因之一,IO或者网络的堵塞或波动都可能造成系统停顿。
文章读到这里,我都绝望了,还好 Martin给出了一个解决的方案:
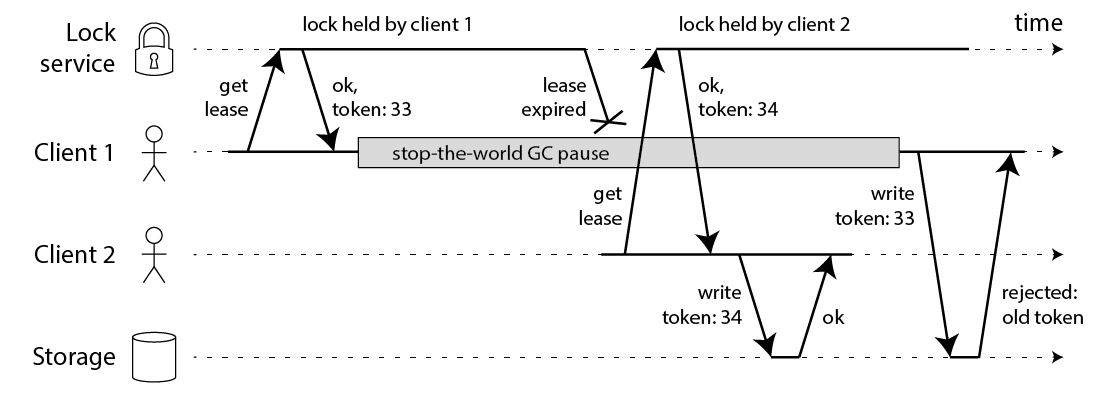
为锁增加一个 token-fencing。
- 获取锁的时候,还需要获取一个递增的token,在上图中 Client 1 还获得了一个 token=33的 fencing。
- 发生了上文的 FGC 问题后,Client 获取了 token=34 的锁。
- 在提交数据的时候,需要判断token的大小,如果token 小于 上一次提交的 token 数据就会被拒绝。
我们其实可以理解这个 token-fencing 就是一个乐观锁,或者一个 CAS。
Martin 还指出了,RedLock 是一个严重依赖系统时钟的分布式系统。
还是这个过期时间的小辫子。如果某个 Redis Master的系统时间发生了错误,造成了它持有的锁提前过期被释放。
- Client 1 从 A、B、C、D、E五个节点中,获取了 A、B、C三个节点获取到锁,我们认为他持有了锁
- 这个时候,由于 B 的系统时间比别的系统走得快,B就会先于其他两个节点优先释放锁。
- Clinet 2 可以从 B、D、E三个节点获取到锁。在整个分布式系统就造成 两个 Client 同时持有锁了。
这个时候 Martin 又提出了一个相当重要的关于分布式系统的设计要点:
好的分布式系统应当是异步的,且不能时间作为安全保障的。因为在分布式系统中有会程序暂停,网络延迟,系统时间错误,这些因数都不能影响分布式系统的安全性,只能影响系统的活性(liveness property)。换句话说,就是在极端情况下,分布式系统顶多在有限的时间内不能给出结果,但是不能给出错误的结果。
所以总结一下 Martin 对 RedLock 的批评:
- 对于提升效率的场景下,RedLock 太重。
- 对于对正确性要求极高的场景下,RedLock 并不能保证正确性。
这个时候感觉醍醐灌顶,简直写的太好了。
RedLock 的作者,同时也Redis 的作者对 Martin的文章也做了回应,条理也是相当的清楚。
antirez 的回应
antirez 看到了 Martin 的文章以后,就写了一篇文章回应。剧情会不会反转呢?
antirez 总结了 Martin 对 RedLock的指控:
- 分布式的锁具有一个自动释放的功能。锁的互斥性,只在过期时间之内有效,锁过期释放以后就会造成多个Client 持有锁。
- RedLock 整个系统是建立在,一个在实际系统无法保证的系统模型上的。在这个例子中就是系统假设时间是同步且可信的。
对于第一个问题:
antirez 洋洋洒洒的写了很多,仔细看半天,也没有解决我心中的疑问。回顾一下RedLock 获取锁的步骤:
- 获取开始时间
- 去各个节点获取锁
- 再次获取时间。
- 计算获取锁的时间,检查获取锁的时间是否小于获取锁的时间。
- 持有锁,该干啥干啥去
如果,程序在1-3步之间发生了阻塞,RedLock可以感知到锁已经过期,没有问题。
如果,程序在第 4 步之后发生了阻塞?怎么办???
答案是,其他具有自动释放锁的分布式锁都没办解决这个问题。
对于第二个指控:
antirez 认为,首先在实际的系统中,从两个方面来看:
- 系统暂停,网络延迟。
- 系统的时间发生阶跃。
对于第一个问题。上文已经提到了,RedLock做了一些微小的工作,但是没办法完全避免。其他带有自动释放的分布式锁也没有办法。
第二个问题,Martin认为系统时间的阶跃主要来自两个方面:
- 人为修改。
- 从NTP服务收到了一个跳跃时时钟更新。
对于人为修改,能说啥呢?人要搞破坏没办法避免。
NTP受到一个阶跃时钟更新,对于这个问题,需要通过运维来保证。需要将阶跃的时间更新到服务器的时候,应当采取小步快跑的方式。多次修改,每次更新时间尽量小。****
说个题外话,读到这里我突然理解了运维同学的邮件:
所以严格来说确实, RedLock建立在了 Time 是可信的模型上,理论上 Time 也是发生错误,但是在现实中,良好的运维和工程一些机制是可以最大限度的保证 Time 可信。
最后, antirez 还打出了一个暴击,既然 Martin 提出的系统使用 fecting token 保证数据的顺序处理。还需要 RedLock,或者别的分布式锁 干啥??
回顾
看完二人的博客来往,感觉就是看武侠戏里面的高手过招,相当得爽快。二人思路清晰,Martin 上来就看到RedLock的死穴,一顿猛打,antirez见招拆招成功化解。
至于二人谁对谁错?
我觉得,每一个系统设计都有自己的侧重或者局限。工程也不是完美的。在现实中工程中不存在完美的解决方案。我们应当深入了解其中的原理,了解解决方案的优缺点。明白选用方案的局限性。是否可以接受方案的局限带来的后果。
架构本来就是一门平衡的艺术。
最后
Martin 推荐使用ZooKeeper 实现分布事务锁。Zookeeper 和 Redis的锁有什么区别? Zookeeper解决了Redis没有解决的问题了么?且听下回分解。