周末补习(一)trie 树
前言
是的,最近我又换工作了,在看新团队的代码的时候发现,同事们为了追求服务的响应时间,在项目中大量的使用了很多高级的数据结构。
作为传统 Curd 程序员,对算法和数据结构已经比较生疏了。如今看到这些”高级的代码“有点汗颜。所以趁周末好好的在家补课,重新复习一下。
文章将会是一个系列,慢慢的查缺补漏。

简介
Trie 树又叫字典查找树。顾名思义,字典查找树,主要解决的就是字符串的查找。有以下两个优势。
- 查找命中的时间复杂度是 O(k),k指的是需要查询的 key 的长度。这里注意和字库的大小无关。
- 对于未命中的字符,只需要查询若干字符就可。
基本数据结构
首先 Trie 树,是一棵树。树是由需要建立的所有词构成。
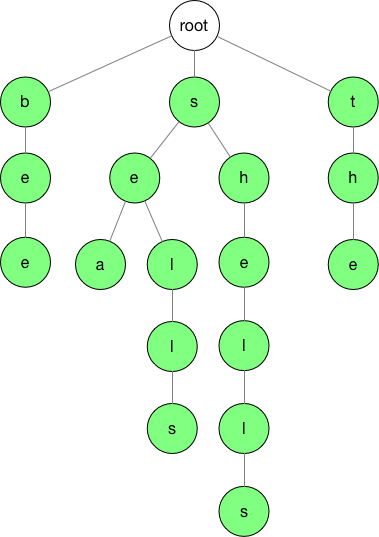
假设我们有,bee 、sea、 shells,she,sells,几个单词。我们可以使用这几个单词构建一棵树。
通过图片我们就可以直观的看出 Trie 的数据结构。这个棵树是由若干节点,链接而成,节点可以指向下一个节点,也可以指向空。从 root 节点开始,顺着链接随便找某个链接往下,直到最低端,经过的路径正好是上文的单词。
数据的代码表示
为了方便使用代码表示。可以考虑每个节点使用数组表示。每个节点都含有一个数组,数组的大小为R,R 是数组的基数,对应每个可能出现的字符。R 的选取取决于报错的字符的类型,如果只包含英文则256 就可以了。如果是中文就需要 65536。
字符和键值都保存在数据结构中。
所以实现代码如下:
1 |
|
Get 和 Put 方法
对于数据结构的键值的读写方法,我可以使用递归的方式进行查询
1 | private Node get(Node x, String key, int d) { |
对于递归的我们需要考虑两个问题。递归的退出的条件是什么,如何进入下一层递归。
对于 Node get(Node x, String key, int d),入参 x 是当前的节点,key 是需要查找的字字符串,d 是目前递归到的层数,也可以理解为,我们逐个遍历 key 的时候的下标。
我们按照注释逐行讲解一下:
- 递归跳出的条件之一,就是发现上一次查询指向的节点是空的,说明没有找到匹配的字符串。所以直接返回一个 null,表示没有匹配上。
- 递归跳出的条件之二,就是key值已经遍历完了。并且找到了对应的 value。可喜可贺。
- 这里的 c 表示的就是key在下标为 d 的时候对应的字符。因为我们的 root 是第 0 个,所以遍历 key的 c 是从1开始。
- 递归调用 get 方法。将 x 的下一个节点传入方法,同时下标 d 加 1。
我们再来看 put 方法:
1 | private Node put(Node x, String key, Value val,int d) { |
put 方法和 get 方法非常类似,习惯上来说我们在保存数据的时候,都需要先查询一下看看数据存不存在,如果存在直接返回,如果不存在再插入数据。trie 数的插入也是这个思路。
我们按照注释逐行讲解一下:
- 如果当前节点为空,则在当前节点插入一个空 value。注意:这里是新建一个节点,在这个新节点上插入空的 value,而不是插入一个空节点,注意区分。
- 同理,如果d == key 的长度,表示已经将 key 遍历完了,需要把 key 对应的值保存在节点上了。
- 和 Get 一致,略。
- 递归调用 put 方法,将 x 的下一个节点传入方法,同时下标 d 加 1。然后逐层放回。
看完这 Put 和 Get 方法。我们再回顾一下 trid 的性质。
查询的次数,只和代码中的 key 的长度有关,与字典的大小没有关系。
如果没有命中的数据,查询的次数小于等于 key 的长度 。
应用
这里先着重介绍一下 trie 树的其中一个应用 ”前缀匹配“。
我们在搜索框里面输入一个词的时候,通常会收到提示的列表如下图:
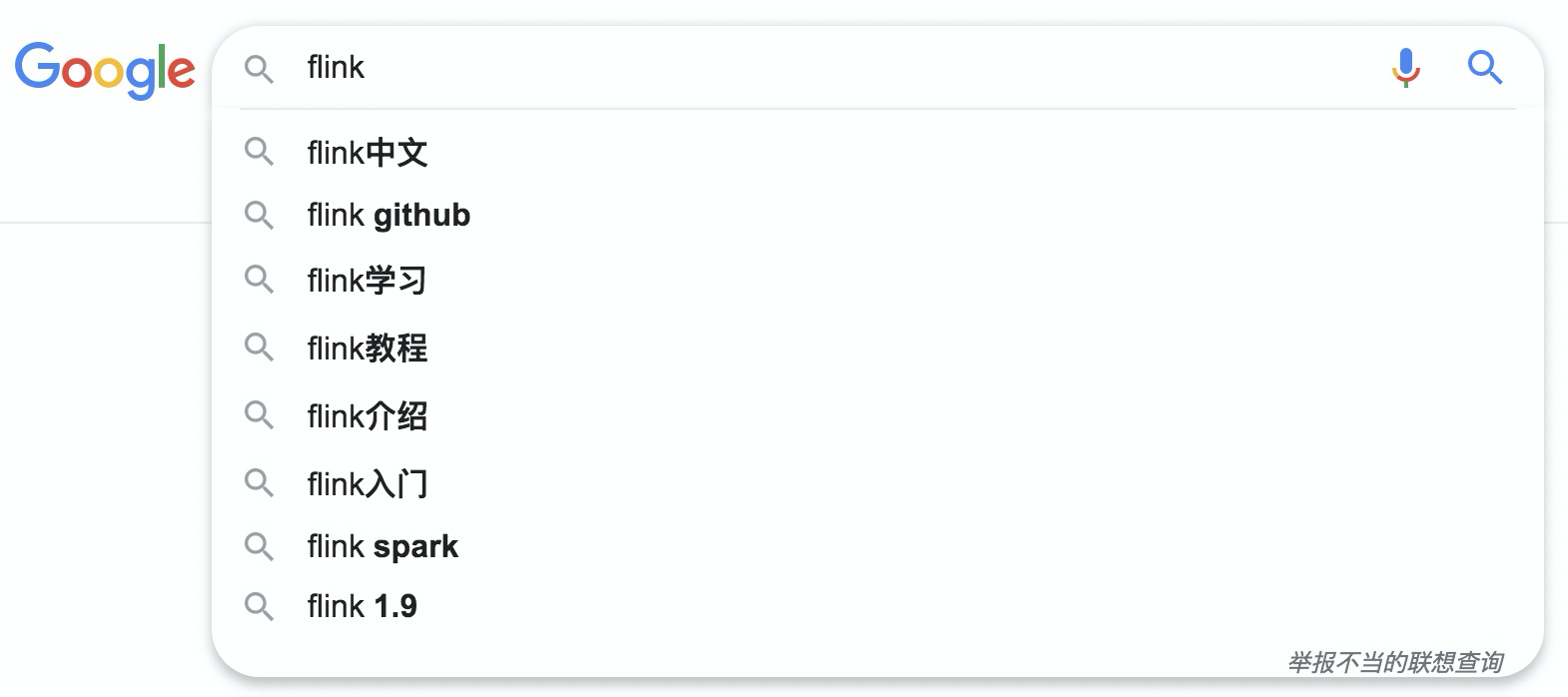
输入 flink 的时候,搜索引擎会提示联想出用户可能的输入,提升用户体验。
有了上面的 Trie 树的介绍。具体实现这个功能就比较简单了。
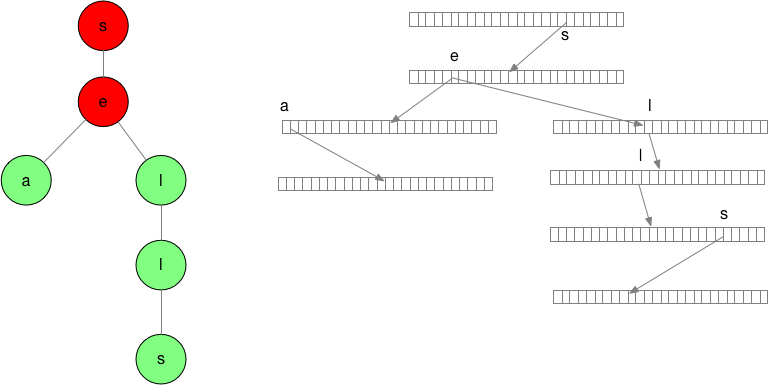
回到我们原有的例子,假设词库里面有单词 bee 、sea、 shells,she,sells。如果用户输入 se 两个字符,我们应该会向用户提示 se 开始的词: sea 和 sells。
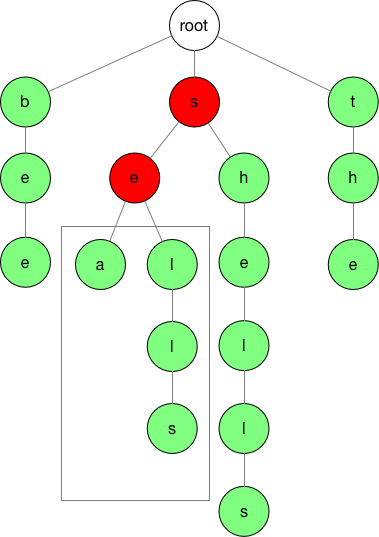
结合图片,我们要找到 se 开头的字符。我们首先要定位出图中红色的链条,然后把红色 e 的所有子链找出来。当然如果 e 的子链特别多,我们就需要考虑对子链进行截断。具体怎么截断我们以后会的文章里面可能会讲解。
我们先看代码:
1 | private void collect(Node x, String pre, Queue<String> q){ |
逐条解释一下:
- 初始化找一个容器存储起来。
- 其中的
get(root,pre,0)就是为了找出上图中标红的 e节点。然后把 e 节点放到collect()方法中。 - 递归的退出条件就是到达某一个链的最子节点。
- 如果 x 节点的 val 不为空就加入到容器中。
- 暴力的遍历节点上的数组并 c 拼接到 pre 前缀上,递归查找。
我们只需要调用方法 keysWithPrefix("se") 即可。
总结
trie 树在查询的时间复杂度是 O(k) 与词库的大小无关。
但是,有利必有弊。
利用数组表示节点实现的 Trie 树非常占用空间。
如果运用在英文文本处理中,假设单词的平均长度是 11 个字符,R 的大小是 256,100万个键构成的树大约有 2亿5千万个链接数。
是典型的空间换时间应用。
欢迎关注我的微信公众号:
